Rubrical
Advanced AI assessment tool helping geography teachers save 50% of marking time whilst providing better feedback.
GCSE geography teachers were spending up to fifteen hours a week marking long-form responses.
Marking was eating teachers' evenings. Geography teachers were spending whole evenings on long-form responses, with no time left for lesson planning, professional development, or anything outside school. Over forty percent of teachers were considering leaving the profession, and excessive marking workload was the most-cited cause.
Quality suffered as the day went on. After a full teaching day, the depth of feedback a tired teacher could give a student dropped sharply, and the variance between markers on the same script could stretch a full grade band. Students who needed precise, specific feedback got generic comments instead.
The Department for Education commissioned OpenKit as one of sixteen organisations selected for its one-million-pound AI teacher tools fund, under the government's Plan for Change. The brief: cut at least half the time teachers spend on formative assessment, without changing the rubric, without training on student data, and without ever marking a paper unsupervised.
- Marks stay with the teacher. No autonomous decisions.
- No student data leaves the trust's environment.
- Every prediction has to cite specific evidence in the script.
- Must align with KS4 Geography assessment objectives (AO1, AO2, AO3, AO4).
- ISO 27001 controls applied end-to-end, with a DfE-approved DPIA.
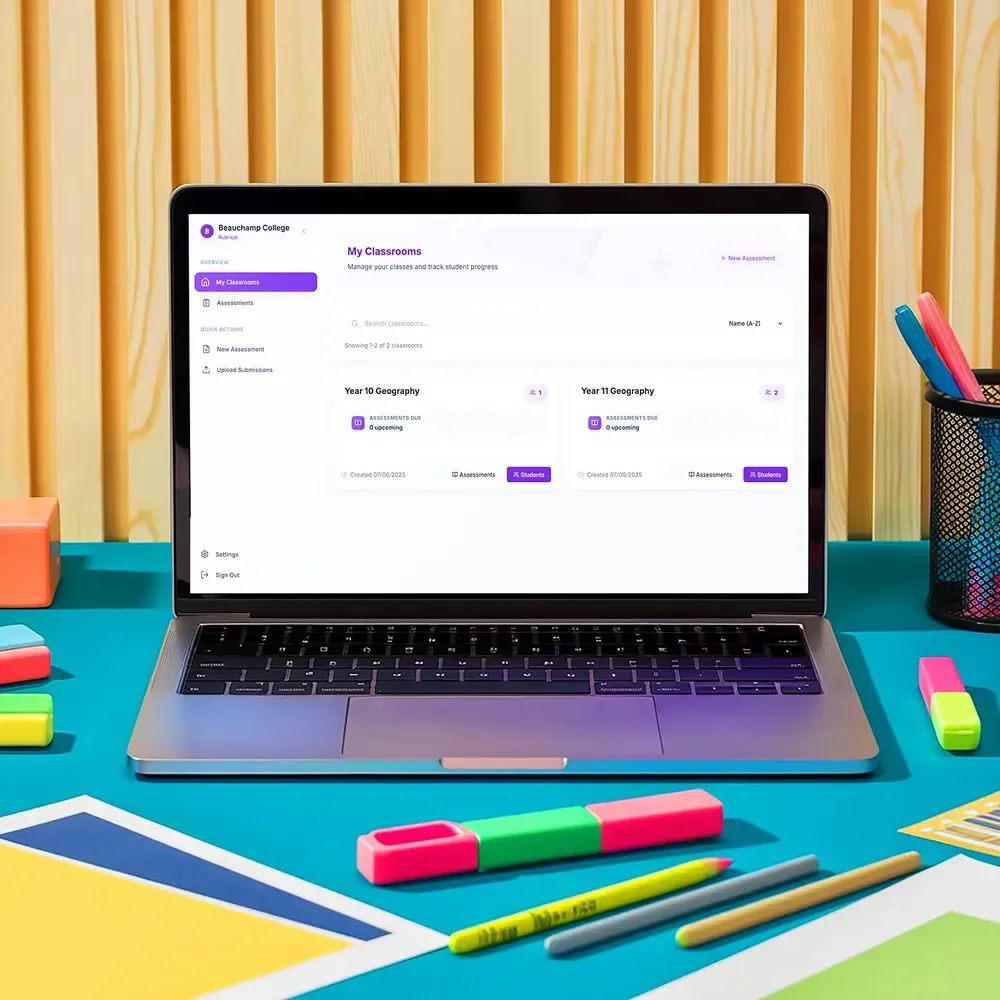
Inside the Rubrical classroom.
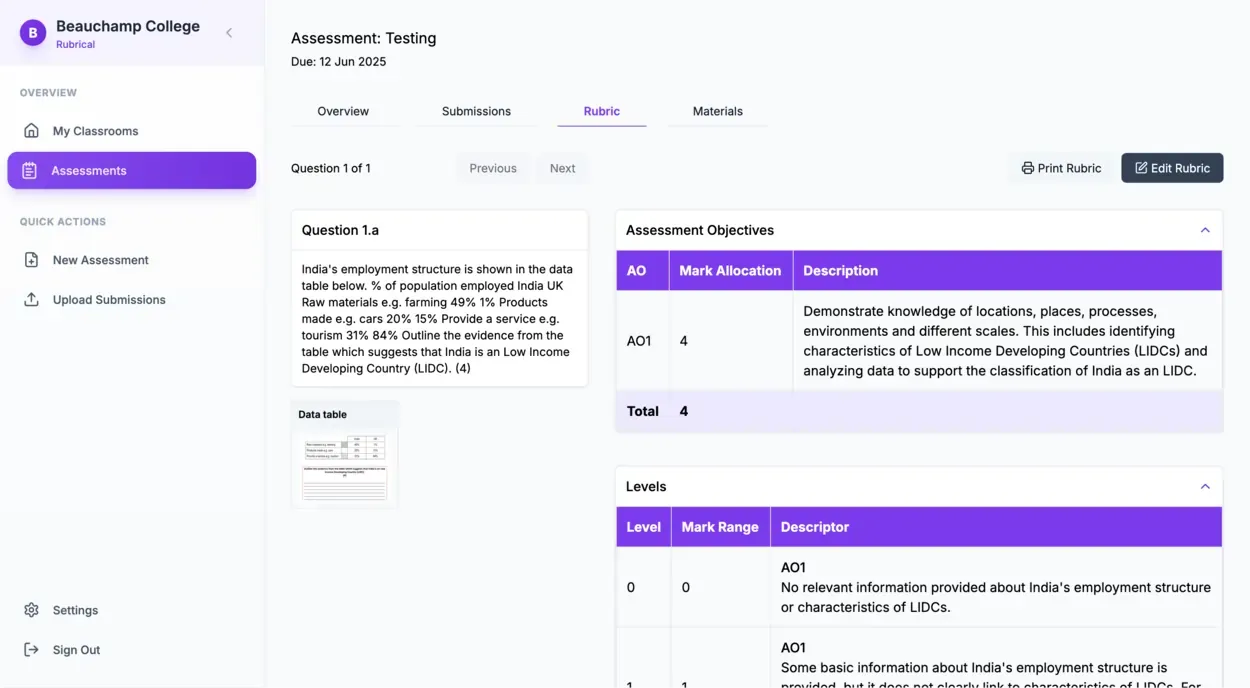
A KS4-aligned rubric from a single assessment question
Upload the question, get a marking rubric aligned to KS4 Geography standards in seconds. The AI understands assessment objectives (AO1 to AO4), mark allocations, command words, and topic-specific criteria. Teachers customise any cell; the system learns from those edits.

Handwritten responses, digitised for marking
OCR tuned for student handwriting handles messy notes, mixed-case lettering, and the kind of scans you actually get from a classroom. Teachers review the digitised text side by side with the original.
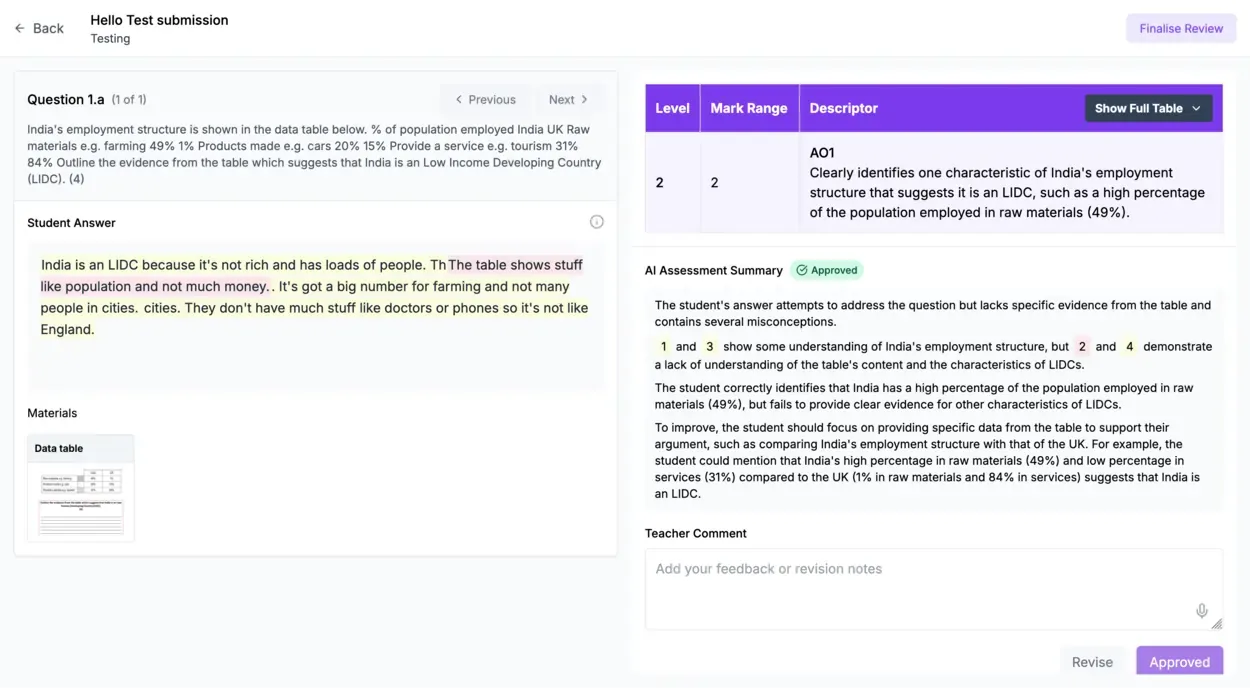
The script with mark-scheme highlights inline
The response is shown with assessment-objective bands highlighted directly in the text. Teachers stay reading the essay rather than flicking between tabs. Marks are suggested with reasoning; teachers accept, edit, or reject with one click or a voice command.
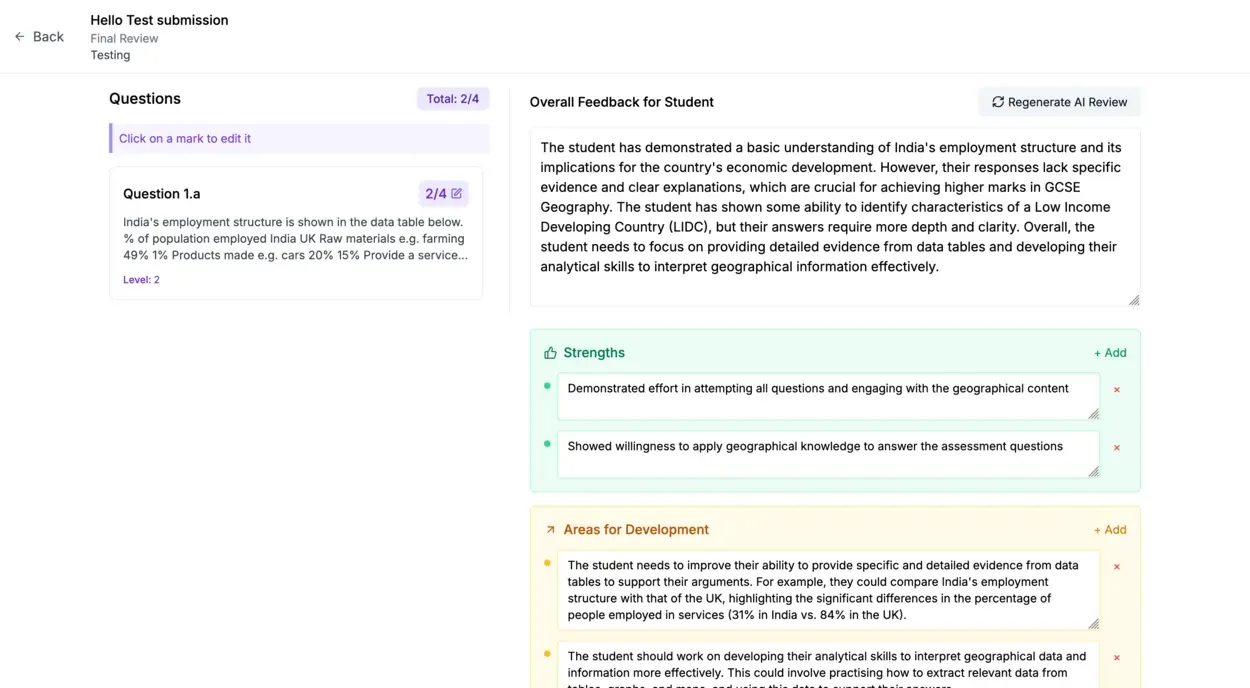
Personalised, defensible feedback per student
Each band carries a confidence score and the evidence it drew on. Strengths are linked to curriculum objectives achieved; improvements are pinpointed with actionable next steps and suggested follow-up exercises. No mark is committed without the teacher accepting it.
Per-student notes feed into future feedback
Teachers add free-text notes about a student ('struggling with map skills', 'excellent at evaluation'). The AI uses them to make subsequent feedback increasingly personal and context-aware.
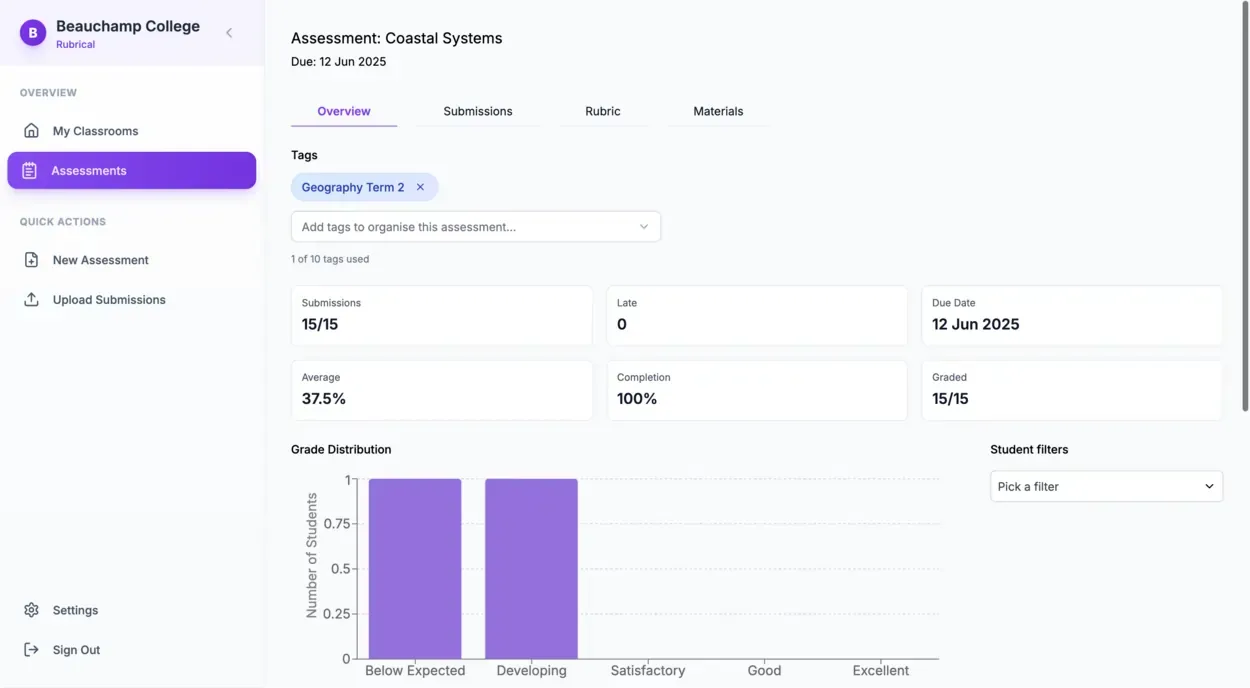
Class-wide strengths, gaps, and progress over time
Progress trends per assessment, topic-level strengths and weaknesses, distribution across the cohort, filtering by performance band. Common misconceptions are surfaced so intervention planning is targeted rather than guesswork.
A private marking workspace built around the teacher, trained on the DfE content store.
Rubrical is a tightly scoped tool: the existing mark scheme, retrieved at query time over a private vector index, plus a generation step that produces a predicted band with citations to specific paragraphs in the student's response. The teacher reviews, edits, accepts. Nothing else.
Everything runs inside the trust's Azure UK tenant. Models sit behind the trust's identity provider via OAuth. Logs are retained for moderation, not for training. The platform integrates with Google Classroom and Microsoft Teams so assignments sync automatically and grades return without manual export; schools on other systems can upload directly. Authorisation takes under five minutes.
We trained on the DfE's content store of curriculum guidance and anonymised pupil work. The KILN evaluation framework let us test model variants for OCR, rubric generation, and marking against the same held-out historical marks senior teachers had already graded. The benchmark below is the result.
The build started with a two-week consulting sprint and over twenty geography teachers. Their feedback shaped the review interface, the analytics dashboard, and the feedback generation system. The teacher advisory board reviews each model refresh.
- Private retrieval over the mark scheme and anonymised exemplar scripts.
- Handwriting OCR pipeline tuned for student script and low-quality scans.
- KILN evaluation framework against held-out historical marks.
- LMS integration: Google Classroom and Microsoft Teams sync; direct upload otherwise.
- Audit trail with source-paragraph citation on every prediction.
- Trust-tenant Azure deployment, trust IdP via OAuth, five-minute setup.
Marking accuracy against held-out historical marks.
Same set of GCSE Geography long-form responses, already graded by senior teachers. Generic AI tools (GPT-4 class, no domain tuning) scored against the same rubric. Rubrical trained on the DfE content store with KILN-based evaluation.
Percentage of marks matching the human grader (higher is better)
Half the marking time, fourteen schools live.
Marking workload
Whole evenings back to the teacher. The marking pile is no longer the bottleneck of the week.
Feedback quality
Personalised, evidence-anchored feedback per student. Every band defensible at moderation, with improvement targets pinpointed to the mark scheme.
Programme partnership
Built under the DfE's one-million-pound AI teacher tools fund. One of sixteen organisations selected nationally.
Trust rollout
Production-grade across a multi-school trust. Trust-wide moderation framework signed off; SLAs in place.
How we delivered it.
Stack
Capabilities
Compliance
From scoping to live.
- Discovery and scopingTwo-week consulting sprint with twenty-plus geography teachers. Audit of the marking rubric, integration constraints, and the evaluation criteria a trust would defend at moderation. Weeks 1-2
- Pilot buildPrivate RAG stack trained on the DfE content store, teacher-in-the-loop UI, KILN evaluation framework against historical marks. Weeks 3-6
- Closed pilotThree schools, two hundred papers a week, weekly feedback cycles. ISO 27001 audit closed in week 8. Weeks 7-9
- Production rolloutFourteen schools live. Trust-wide moderation framework signed off. SLAs in place. Weeks 10-11
- Embedded supportQuarterly model refresh, on-call support, jointly authored impact report. Ongoing
Read another story
All case studies



Bring your team's next AI project to a 30-minute call.
No deck. We listen, sketch a delivery shape, and tell you honestly whether AI is the right tool for the problem.

